In recent years, Nvidia has found a huge amount of success with its pivot to AI, as large language models and GPU-accelerated “premium AI PC” experiences appear to be the hot new thing in 2024. However, newer, smaller companies are vying for its market share, and they are not the ones you may be expecting.
As reported by The Economist, there have been developments in the GPU field outside of the best graphics cards made by Nvidia and AMD for AI computing. That’s because some of today’s large language models run across many setups featuring interconnected GPUs and memory, such as with Cerebras’ hardware.
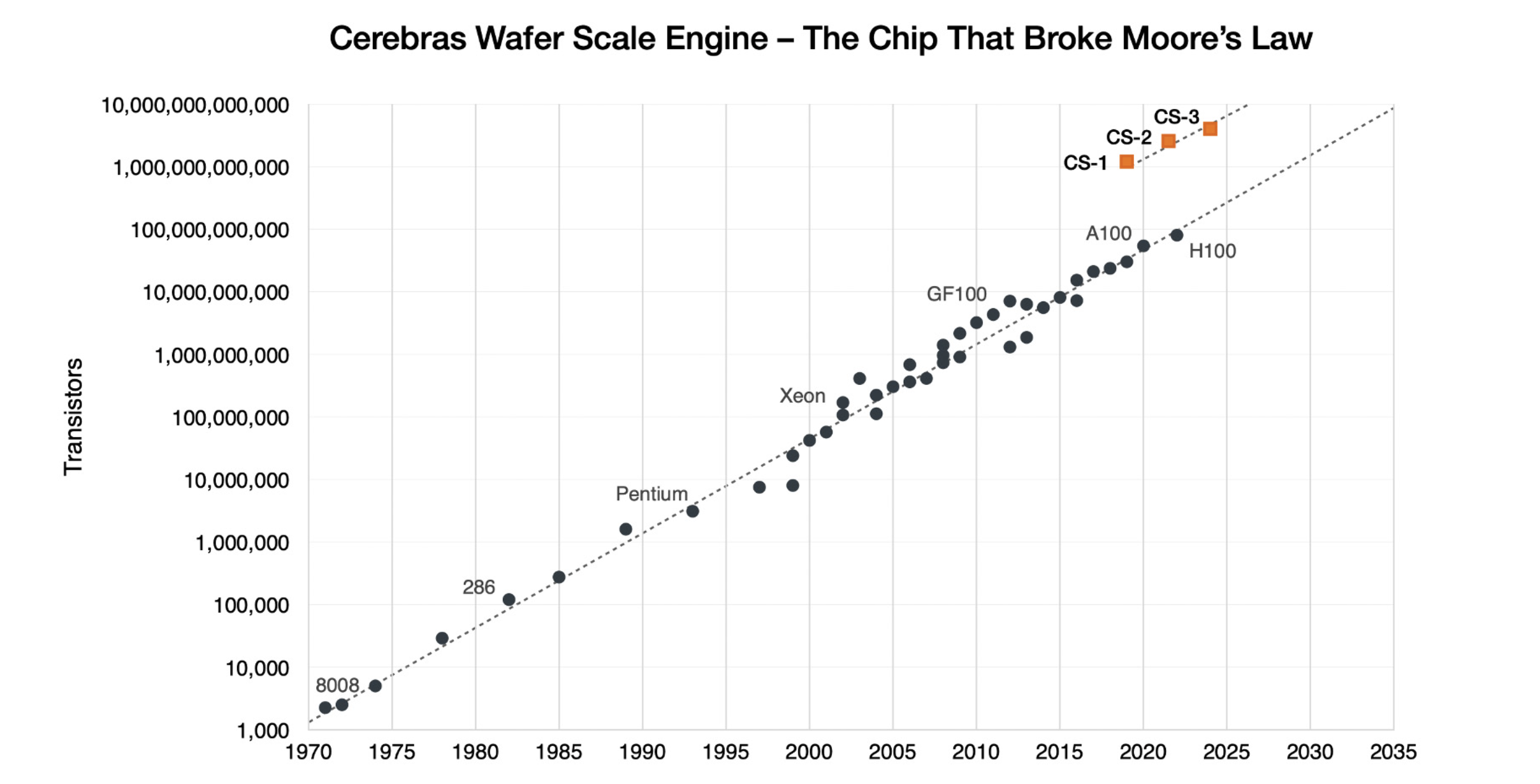
Cerebras Systems Inc. was founded just nine years ago but seems to benefit massively from the recent AI computing boom. It’s innovated in ways that appear to put the current-gen H100 and the upcoming GB200 die to shame with a “single, enormous chip” cable of up to 900,000 GPU cores – such as with its CS-3 chip.
The Cerebras CS-3 chip absolutely dwarfs the double die size of the huge GB200, and is the size of a steering wheel, requiring two hands to hold. It’s been described by the manufacturer as the “world’s fastest and most scalable AI accelerator” which is purpose-built to “train the world’s most advanced AI models”.

Furthermore, the American manufacturer has doubled down stating that its Wafer Scale Engine is “the chip that broke Moore’s Law”. As its internal benchmarks show, the CS-3 sits confidently above the H100 with a total of 10,000,000,000,000 transistors. For reference, the GB200 is set to feature 208,000,000,000, as the CS-3 features a staggering increase of 4,707%.
However, it’s not just Cerebras that is making moves here, as new start-up company Groq is also developing hardware for AI computing, too. Instead of going larger than its competition, it has instead developed what it calls dedicated LPUs (language processing units) which are built to run large language models effectively and quickly.
In the company’s own words, the Groq LPU Inference Engine is an “end-to-end inference system acceleration system, to deliver substantial performance, efficency, and precision in a simple design”. It’s currently running Llama-2 70B, a large-scale generative language and text model, at 300 tokens per user by second.
This feat is possible because of the LPU which resides in the data center in tandem with the CPU and GPU, and this makes low latency and real-time delivery a possibility. Think of it as having a more sophisticated NPU at the heart of a chip just fine-tuned to one specific purpose and on a much grander scale and you’re right on the money.
The profitability of the AI market means competition
Nvidia’s financial success in recent years has been no secret as Team Green was even briefly more valuable than Amazon, even giving Alphabet (Google’s parent company) a run for its money. With figures like that, it’s not surprising that more manufacturers are throwing their hats into the ring and going for the jugular.
Whether the likes of Cerebras and Groq, or even smaller companies such as MatX, have a chance here remains to be seen, however, as AI computing is still largely in its infancy, now is the time we’ll be seeing the most experimentation with how the hardware can cater to the end user. Some will scale up, others will work smarter.
You may also like…
Go to Source
Author:
